

Most websites have multiple variations of URLs that lead to the same page. Look, for example, at the following URLs:
https://www.mycompany.com
https://mycompany.com
http://mycompany.com
https://www.mycompany.com/home
All of these URLs are referring to the same homepage of your website but are slightly different. This is problematic for most enterprise search engines, and specifically Mindbreeze, because the URL is used as the unique key to identify a piece of content. This results in the same page being duplicated in the search results.
To combat this problem, Mindbreeze allows you to overwrite what is used as the unique key for a specific index. The best solution is to use canonical URLs within your website, and to tell Mindbreeze to use these canonical URLs as the unique key.
To do this, Mindbreeze uses what they call Extract Metadata. Using XPath expressions, you can tell the Mindbreeze crawler where to find structured information within your pages.
Mindbreeze uses “header/mes:key” as the unique identifier for an item within the Mindbreeze index, so we simply need to overwrite that metadata field with the canonical URL from our page.
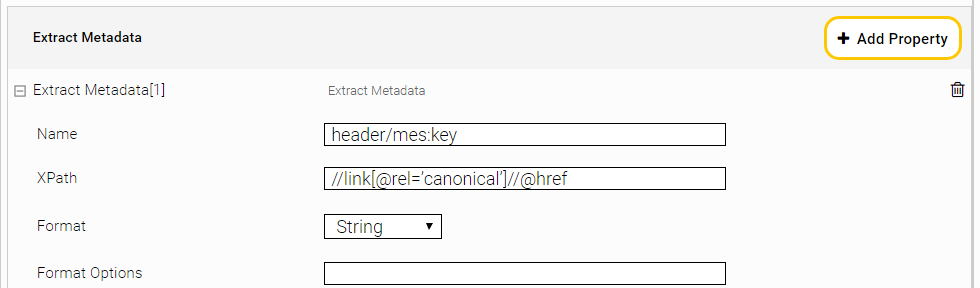
The following configuration needs to be added to the crawler configuration in which canonical URLs should be used:
Name: header/mes:key
XPath: //link[@rel=’canonical’]//@href
Format: String
Format Options:
Applying this small change within your Mindbreeze crawler configuration can immediately improve website search results. Users won’t have to waste time sorting through duplicate information, tracking metrics for the page should be easier, and you can improve overall Mindbreeze search crawler performance as it will no longer spend time crawling duplicate pages.
0 Comments